
![]()
In my last post I discussed the problems with managing configurations from multiple vendors, both from the perspective of parsing the configurations for my own nefarious purposes and that of configuring those network devices. The aim would be to configure the network devices using an abstracted (descriptive) configuration – that is, something describing what we want to configure rather than how to configure it on a particular platform, and letting an underlying layer convert that into an actual implementation, much in the same way that Puppet describes what you want to have happen, but it’s up to the Puppet Agent to figure out how to make that happen on a specific platform.
Having had a long conversation with a colleague about these challenges with network configuration management I was pleased to hear from Tail-f when I attended Networking Field Day 7 earlier this year, as it seems like they have a product that addresses some of these needs. I’m not going to regurgitate most of what’s in the presentation, though I’ll link to the videos and strongly recommend that you take some time to watch them, because they were impressive. Instead I’m interesting in how the product might meet the aims I laid out in my last post.
Flashback
In case you had forgotten, here are the list of “nice to haves” in a network configuration management solution, as outlined in the previous post:
- Ability to store configurations in a non-vendor-specific format
- Ability to make OS-independent configuration changes based on abstracted requirements rather than specifying actual OS-dependent implementation steps
- Ability to know if a change succeeds or fails, and determine how to act in the event of failure
- A tool that can use whatever features are available on each platform, perhaps in an preference order, e.g. NETCONF > SSH CLI > Out of Band Serial CLI
- Ability to roll back changes? Since I want to describe my change in a more abstract sense, I’m going to define by requirements as “if something goes wrong, revert to the previous configuration”, so the tool needs to be able to handle implementing that part too.
What’s in a Name?
I have to say this. When I hear “Tail-f”, I think of log files. After all, tail -f is the command you use in a un*x system to watch a file in real time as it’s updated, usually for files like syslog. When I first heard that the Swedish company ‘Tail-f’ was presenting at NFD7 I was confused why as log management company would be presenting to us. My mistake, of course; the name belies the focus.
Tail-f offer just two products. The first is ConfD, which handles NETCONF requests, and is sold for OEM use. While I don’t believe Tail-f offers an official customer list, the indication was that if you’ve used NETCONF you’ve almost certainly interacted with their OEM confd service.
The second product is the one I’m more interested in, Network Control System (NCS). From the sounds of it, this may fulfill many of the needs I had already sketched out.
John’s Checklist
Let’s check how Tail-f’s NCS product stacks up against my list.
Storing Configurations
Basically, no; from what I understand the configurations are still native to the vendor. From some of the code we saw, it looked like this in pseudo-XML:
<configuration>
<ios configuration>
[the IOS config]
</ios configuration>
</configuration>
I’m not surprised, because I don’t think we’re in a position (yet) to have one abstracted configuration format that could possibly support all the vendor configurations. I’m not even truly sure if it’s possible, although as I indicated in my last post, I think we can get close for the vast bulk of configurations. Until then, it’s a no.
OS-Independent Changes
Yes, this is absolutely possible. The device-specific files that sit behind NCS allow the tool to figure out how to make changes on multiple platforms. Here’s an image from the presentation at NFD7. What you can see is that the configuration for SNMP can be mapped into NETCONF templates for multiple platforms:
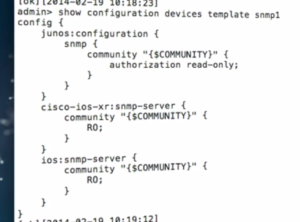 The ways in which this feature could be useful are pretty extensive. Have firewall tiers from different vendors supporting the same flows? One ACL can be configured and pushed out to both types. More importantly from an automation point of view, you can have a device that determines the necessary change in a single format, pushes it to NCS, and lets NCS deal with the implementation of that change on the end device.
The ways in which this feature could be useful are pretty extensive. Have firewall tiers from different vendors supporting the same flows? One ACL can be configured and pushed out to both types. More importantly from an automation point of view, you can have a device that determines the necessary change in a single format, pushes it to NCS, and lets NCS deal with the implementation of that change on the end device.
Act on Failure
Failure could occur in a number of ways. Maybe half way through the change, a command is rejected. Perhaps you can’t connect to to device. NCS says they can protect against those issues when deploying a change, as they use a transactional model with atomic change sets. As a reminder, here’s how Wikipedia (lazy reference, I know) defines atomicity:
In an atomic transaction, a series of database operations either all occur, or nothing occurs.
In other words, NCS wants to ensure that your entire change is executed successfully. If it’s not, it can roll the configuration back to its previous state. If you are deploying changes on a lot of devices you can also determine whether to roll back all the other changes when a failure occurs. This may be helpful if, for example, you are rolling out a routing change and discover that the change is not successful on some devices; you can revert all the previous changes and restore every device to their previous state.
Tail-f say that if a device offers its own transactional features (e.g. Junos uses a candidate configuration which you then commit, where the entire commit either succeeds or fails) then that mechanism would be used to guarantee an atomic transaction. For other operating systems (e.g. IOS) it is NCS that has to ensure that the change is entirely successful.
Connect in a Variety of Ways
Tail-f again seems to have thought ahead, as NCS supports multiple connectivity methods. Obviously, to prevent against a change locking you out of a device it’s always nicer to have an isolated out of band management network rather than managing through production paths. However, if a change means that NCS can no longer access a device, it has the ability to use alternative connection paths instead.
Rollbacks
One of the questions we asked at NFD7 was about how rollback was accomplished; did NCS use the Junos “rollback 1” command, for example? The answer was a very firm “no”. NCS keeps track of the change that was made – as a description, not the actual commands though. This is important, as if there were other changes made to the device between configuration and rollback, a raw diff might be inaccurate. By storing the service request (the what rather than the how), the configuration necessary to reverse the previous change can be calculated based on the latest actual configuration.
You cannot just put “no” or “delete” in front of any changed lines though; you need more intelligence than that, and incredibly, NCS appears to have it. One of the demos given in the videos below showed a BGP ASN change, where the service request (the what) is along the lines of “Change the BGP ASN from 1 to 100”:
Configuration BEFORE: router bgp 1 network 10.0.0.0 neighbor 1.2.3.4 remote-as 73 Configuration AFTER: router bgp 100 network 10.0.0.0 neighbor 1.2.3.4 remote-as 73
Intelligence is needed in both the rollout and rollback calculations; you can’t just redefine the ASN in place. Instead you have to delete the bgp process then create a new one, and then – and this is the trick – remember to re-add the neighbor and network statements that were previously there, under the new BGP process. NCS is smart enough to realize this, and generates the configuration correctly.
There is a caveat here though which is that often the behavior of different software releases can be different, and the nuance of which command to best use to remove configuration that was added can make rollbacks tricky. As I’ve mentioned before, the rollback for this addition to an OSPF process:
redistribute bgp 1234 subnets route-map RM->BGP-TO-OSPF
is not:
no redistribute bgp 1234 subnets route-map RM->BGP-TO-OSPF
All that does is to remove the route-map. You need to know that the correct way to remove that command is in fact:
no redistribute bgp
NCS uses modeling files for each platform/OS release that define exactly this kind of thing. The catch from my perspective is that when the OS is updated, it’s potentially down to you to update those definition files because tail-f do not provide the updates (although you can pay them to create them). This is good and bad; the up side is that this is a customer-driven model where device files can be created by anybody for pretty much any device/OS combination, and you are not limited to what tail-f provides. The down side is that you may not want to devote time to updating the definitions, or if customers share their own updated models (presumably not the ones they paid for) – and this is happening to some extent on github already, they said – you have to decide whether to trust somebody else to get it right. Maybe there’s a market here for somebody with the right skills to create those definition files and license them to tail-f NCS users?
Middleware
NCS is really middleware. Yes, it’s a controller of sorts, though not in the OpenFlow sense.
 The role of NCS is to convert requirements into implementable configurations, and it seems pretty capable based on the discussions and demos at NFD7. So where do requirements come from? NCS offers three interfaces itself; a Web UI and a CLI. I said three interfaces because the CLI can run in a Junos-alike mode or an IOS-alike mode. All three methods end up with the same internal requirement being defined and the same implementation being executed, so you can pick the one you like best and use it. Alternatively, you could use a third party tool to generate requirements and pass them to NCS. With regard to Northbound interfaces, tail-f says that the following interfaces are auto-rendered for all services and devices:
The role of NCS is to convert requirements into implementable configurations, and it seems pretty capable based on the discussions and demos at NFD7. So where do requirements come from? NCS offers three interfaces itself; a Web UI and a CLI. I said three interfaces because the CLI can run in a Junos-alike mode or an IOS-alike mode. All three methods end up with the same internal requirement being defined and the same implementation being executed, so you can pick the one you like best and use it. Alternatively, you could use a third party tool to generate requirements and pass them to NCS. With regard to Northbound interfaces, tail-f says that the following interfaces are auto-rendered for all services and devices:
- CLI: for network engineers that prefer a Juniper or Cisco style command-line interface
- Web interface: for network engineers that prefer a graphical interface (the Web interface is highly customizable)
- REST: for programmatic access (exactly the same feature set as the CLI and Web interface)
- Java/C: for building custom applications and service provisioning logic
- JavaScript: for embedding NCS functions in portals
- NETCONF: for importing and exporting XML configurations
- SNMP: for reading status and receiving NCS alarms
- Python: for scripting network wide configuration changes
Additionally, the NCS FAQ adds that “[the] Havanna release of OpenStack introduced a NCS Mechanism Driver that maps the OpenStack Neutron network model changes to NCS REST calls. NCS can then map these changes to a multi-vendor network.” Neat.
Do You Take Checks?
Price is always the big stumbling block with good tools. There’s no web store to purchase NCS, so it’s hard to know for sure what it costs. However, I did find what looked like notes for a buyers guide online that said “Tail-f offers NCS in two business models; upfront fee or subscription based licensing. Price depends on on product features and the size and complexity of the network to be managed. As an example, NCS for an Enterprise network with up to 200 access switches would cost $4,900 per month on subscription basis.” I have no idea if that’s still valid (the dates suggest it was a year ago), uses US dollars (it probably does), or is representative of current pricing, but it gives a ball park idea I guess.
I’m Almost Happy!
I like the NCS product. The demos are slick and give an intriguing insight into the power of this kind of system for network maintenance. Hooking NCS into OpenStack or your own automation tools could prove to be a huge time saver. What NCS won’t do of course is stop you doing something stupid. If you tell it to kill off BGP on every device, I’m sure it will do just what you ask it to do. But at least you can hopefully do a rollback just as easily!
Alternatives?
Obviously Tail-f NCS isn’t the only solution, but it’s certainly very interesting in terms of the requirements I set out at the start. In an upcoming post I’ll take a look at least one more possible way to approach this problem.
NFD 7 Videos
As I said before, I didn’t want to simply regurgitate the videos so I’ve left lots of stuff out for you to see for yourself. The presentations are available below, and I encourage viewing ideally of all of them, but if you have to pick one, go for the demo and watch it in HD so you can see the screen clearly. I think you’ll get a lot of out of it, even if you don’t buy the product.
Introduction to Tail-F NCS
Tail-F Discuss Network Element Drivers (NEDs)
Tail-F Demo at NFD7
Disclosures
Tail-f was a paid presenter at Networking Field Day 7, and while I received no compensation for my attendance at this event, my travel, accommodation and meals were paid for by Tech Field Day. I was explicitly not required or obligated to blog, tweet, or otherwise write about or endorse the sponsors, but if I choose to do so I am free to give my honest opinions about the vendors and their products, whether positive or negative.
Please see my Disclosures page for more information.
This was great, thanks!