
![]()
Cumulus Networks announced today that in conjunction with Dell and Red Hat, it has created a 300+ node OpenStack pod using standard open source DevOps tools to manage the deployment from top to bottom (i.e. from the spine switch down to the compute node). I thought that was interesting enough to justify a quick post.
All Linux, All The Time
I visited with Cumulus Linux as part of Networking Field Day 9 and learned two very important things:
- Cumulus co-founder, CEO (at the time), and now CTO, JR Rivers makes a mean cup of espresso;
- The culture at Cumulus is all about standards. It was expressed repeatedly that Cumulus want to ensure that their linux is absolutely standard, so the file system hierarchy should be the standard, configuration files should be where they normally are, and so forth. A system that doesn’t follow those guidelines becomes a special snowflake that can’t be supported by regular tools and, as you’ll see, this attitude has paid dividends in this solution.
The idea of this software stack demo is to take linux-based switches (Dell brite-box
Cumulus-certified hardware running the Cumulus Linux OS) and connect in linux-based compute resources (Dell PowerEdge servers running Red Hat linux). Running a standardized (non-snowflake) linux top to bottom of the stack means that both the switches and the servers can potentially be managed by the same tools. Clever, right?
Leaf / Spine Architecture and VXLAN
By now I think most people understand that the ubiquitous leaf / spine architecture has one underlying requirement to make it work: routing. One way or another, we need equal cost paths between endpoints so that the leaf / spine fabric can load share the data using Equal Cost Multi Path (ECMP). There are various ways to do that, but at layer 2 most will either encapsulate each frame in another Ethernet frame or will add headers to the frame to allow it to be handled appropriately at each hop. This way we get to keep our VLANs but can scale layer 2 domains across a massive data center Ethernet fabric. The only problem is that there are a number of magical encapsulation methods, which means more special snowflakes, which means non-standardized configuration.
The solution in this case is to make the entire leaf / spine fabric run at layer 3 only. This is a routed fabric, pure and simple. Servers connect to the fabric using, effectively, an access IP (a way to get to the server) but not with the actual VM IP addresses within, and not with layer 2 connections. So that servers can be ‘adjacent’ to one another at Layer 2, the servers can encapsulate that traffic using VXLAN, so from endpoint to endpoint, layer 2 frames are IP-encapsulated and can be easily routed across the layer 3 fabric. Of course this also means that your layer 2 endpoint (the VMs) can also move anywhere in the fabric without too many worries about where they are physically hosted within the pod.
End-Point Routing
If the above is a one-two knockout punch, then the addition of the open source Cumulus quagga routing service to the linux end hosts is presumably the equivalent of kicking an opponent while they’re down. Each host can have multiple uplinks to the layer 3 fabric and because they participate in the routing protocol(s), host IPs can be directly injected into the fabric by the endpoint, again facilitating mobility for the compute resources. Although not mentioned, I can also imagine that having routing on the hosts could also allow for multiple routed uplinks from the switches (more than the usual 2 links) if desired, and thus the ability if wanted to control traffic on a more granular level than just accepting ECMP, if that’s useful in a particular environment. Certainly it’s more flexible than having HSRP, VRRP, GLBP or similar as a server gateway, as it permits ECMP all the way to the server for both ingress and egress traffic.
Update 4/14/2016: Andrius Benokraitis from Cumulus shared this link for anybody interested in learning more about routing on the host: Routing on the Host: An Introduction.
Ultimately, the pod looks like this (diagram courtesy of Cumulus Networks):
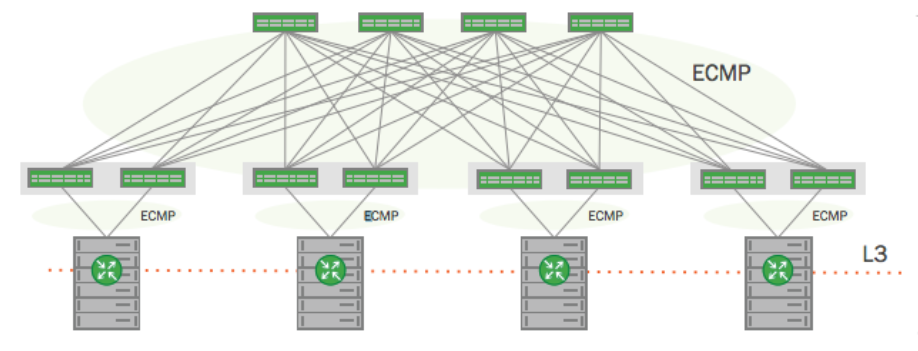
Open Source Software Defined Data Center
OSSDDC? I’m not sure if that abbreviation exists, but let’s run with that for now. In theory everything described so far can be accomplished if you spend the time to configure it, but part of the purpose of this exercise was to create a large-scale OpenStack deployment that did not require a proprietary SDN fabric solution (including, ironically enough, Cumulus’ own L2/L3 fabric solution). Avoiding the SDN fabric means it’s easier to use the existing DevOps tools to do the work for you, and in this case the network and compute nodes were deployed using a tool chain containing Red Hat OpenStack, Red Hat Ansible and git.
The achievement here is to have used OpenStack (and specifically, native OpenStack Neutron) to deploy a 300-server pod with over 8.6Tbps of network bandwidth, I am told. I don’t know the basis for that figure, and in fairness I should say that I have not asked, but at a minimum there were 300 servers each with 2 x 10Gbps connections to the fabric, which I believe makes for a potential of 6Tbps of throughput in this example topology, and it sounds like there were server ports going spare.
Update 4/14/2016: JR Rivers (the man with the coffee machine… and oh, also a co-founder of Cumulus) explains in the comments:
The 8.6Tbps comes from… 2 switches/rack * 6 uplinks/switch * 9 racks * 2 * 40 Gbps/uplink (NOTE: the factor of 2 at the end is a confusing but defacto multiplier to account for the fact that each uplink has 40Gbps of BW in each direction). That same logic, when applied to your “server connect” calculation results in 12 Tbps of BW.
Connecting To The Outside World
While it was not referenced in the release from Cumulus, my assumption is that in order for this VXLAN-based solution to speak to non-VXLAN hosts outside the pod, it would be possible to use the existing VTEP capabilities of Cumulus Linux to act as gateways. If I get confirmation (or otherwise) I’ll let you know, as this is a guess on my part.
Update 4/14/2016: Thankfully, Nolan Leake from Cumulus (also a co-founder, espresso quality TBD), is on hand to give a really helpful explanation. I’m just going to quote him here so I don’t mess it up:
You guessed right about HW VTEP support. DreamHost, for example, uses a pair of T2 switches as VTEPs to connect their “Internet” VXLAN network to their upstream routers. This can also be used to connect appliances like HW load balancers and firewalls, or non-virtualized servers.
There are two basic ways to do it, depending on which virtual switch you’re using on the hypervisors.
DreamCompute uses LinuxBridge, so they use “vxfld”, our BUM packet replicator running on the OpenStack controller cluster. Another option is to run it on some of the spine switches.
This RedHat demo used OpenVSwitch, which simply floods all BUM packets to all VTEPs, both to the software vswitch VTEPs in the hypervisors, and any HW VTEPs. This creates a configuration wrinkle for HW VTEPs, because they now need a list of the VTEP IP of all the vswitches. This can be extracted programmatically from Neutron.
May I just add that, as a Brit, I still laugh every time I see “BUM” in technical text.
My 2 Bits
This was supposed to be a short post, wasn’t it? I hope I’ve done justice to the solution by trying to translate the press release into something more tangible. Whether this is the way of the future I don’t know, but certainly it demonstrates an interesting approach to have linux throughout the stack, routing all the way down to the server, and management via OpenStack without having to add in a plethora of plugins / drivers.
The press release is here and if you’re going to the OpenStack Summit in Austin this month, you can hear more about this demonstration in a beginner level session.
Update 4/14/2016: Huge thanks to Nolan, Andrius and JR for stopping by and filling in some gaps here!
Disclosures
Cumulus Networks presented and–more importantly–provided decent espresso, at Networking Field Day 9. However, this article is unrelated to the material presented on that occasion.
You can read more here if you would like.
You guessed right about HW VTEP support. DreamHost, for example, uses a pair of T2 switches as VTEPs to connect their “Internet” VXLAN network to their upstream routers. This can also be used to connect appliances like HW load balancers and firewalls, or non-virtualized servers.
There are two basic ways to do it, depending on which virtual switch you’re using on the hypervisors.
DreamCompute uses LinuxBridge, so they use “vxfld”, our BUM packet replicator running on the OpenStack controller cluster. Another option is to run it on some of the spine switches.
This RedHat demo used OpenVSwitch, which simply floods all BUM packets to all VTEPs, both to the software vswitch VTEPs in the hypervisors, and any HW VTEPs. This creates a configuration wrinkle for HW VTEPs, because they now need a list of the VTEP IP of all the vswitches. This can be extracted programmatically from Neutron.
Thank you, Nolan! I’m flattered that you took time to read my post.
I appreciate the clarification and additional information on how this works. The link between OpenVSwitch’s behavior and the need to extract the VTEPs from Neutron almost closes the circle on the benefits of having deployed this with OpenStack in the first place. Gotta love it. I’ll update the article with your response so it’s inline for future readers. Thanks again!
Andrius Benokraitis from Cumulus got in touch with me and said that if readers are interested in understanding more about routing on the host, there’s a good link here:
Routing on the Host: An Introduction
https://support.cumulusnetworks.com/hc/en-us/articles/216805858
Thanks, Andrius!
Wanted to clarify the “networking math” that caught your eye. The 8.6Tbps comes from… 2 switches/rack * 6 uplinks/switch * 9 racks * 2 * 40 Gbps/uplink (NOTE: the factor of 2 at the end is a confusing but defacto multiplier to account for the fact that each uplink has 40Gbps of BW in each direction). That same logic, when applied to your “server connect” calculation results in 12 Tbps of BW.
Dang it, I should not have forgotten the bidirectional factor. Thank you! I will update with your information. (And yo, again, thanks for the espresso 😉