
Over the last few months, I’ve noticed that some pages on this site have been returning what appear to be corrupted pages, looking something like this:

Or like this:
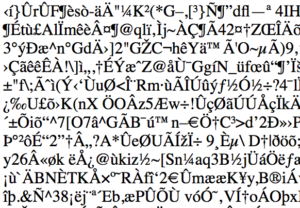
Pretty, aren’t they? Typically if the user hits refresh the page will come back as it should have done first time. I’ve been working for many weeks now to track down why this was happening. One thing I noted is that the corrupted files were smaller than the non-corrupted equivalent, suggesting that the file was either truncated or, more likely, compressed. Opening a downloaded file in a text editor showed that the header of these corrupted pages begins like this:

Some of you are probably feeling smug right now because you know that the first three bytes of a gzip file are 1F 8B 08. The ASCII code for 0x1F is Ctrl-_; there’s no code for 0x8B; ASCII 0x08 is the same as Ctrl-H (i.e. backspace). This should look familiar in the image above: ^_ <8B> ^H. In other words, the client is receiving a GZIPped version of the page but presumably was told that the mime type was text/html. The end result is the garbled mess we saw above. So now I knew what was happening, but still didn’t know how.
As with any blind troubleshooting (i.e. I don’t have the expertise to debug it directly), I went through a process of eliminating one element at a time. After a short while I was able to confirm that the problem was not being introduced by Cloudflare (I had wondered after their recent issues), and tracked the issue down to the W3 Total Cache WordPress optimization plugin.
With that knowledge in hand, I was finally able to find other users complaining about the same thing, and came across a discussion entitled “W3TC Causes Garbled Code Display on Pages.” I was not alone! One page 2, user Kimberley (@amiga500) shared a fix that was created on the W3 Total Cache Fixed Community. I’ll share that fix here in case anybody else has the same issue before, presumably, it gets fixed in the main codebase.
The Fix
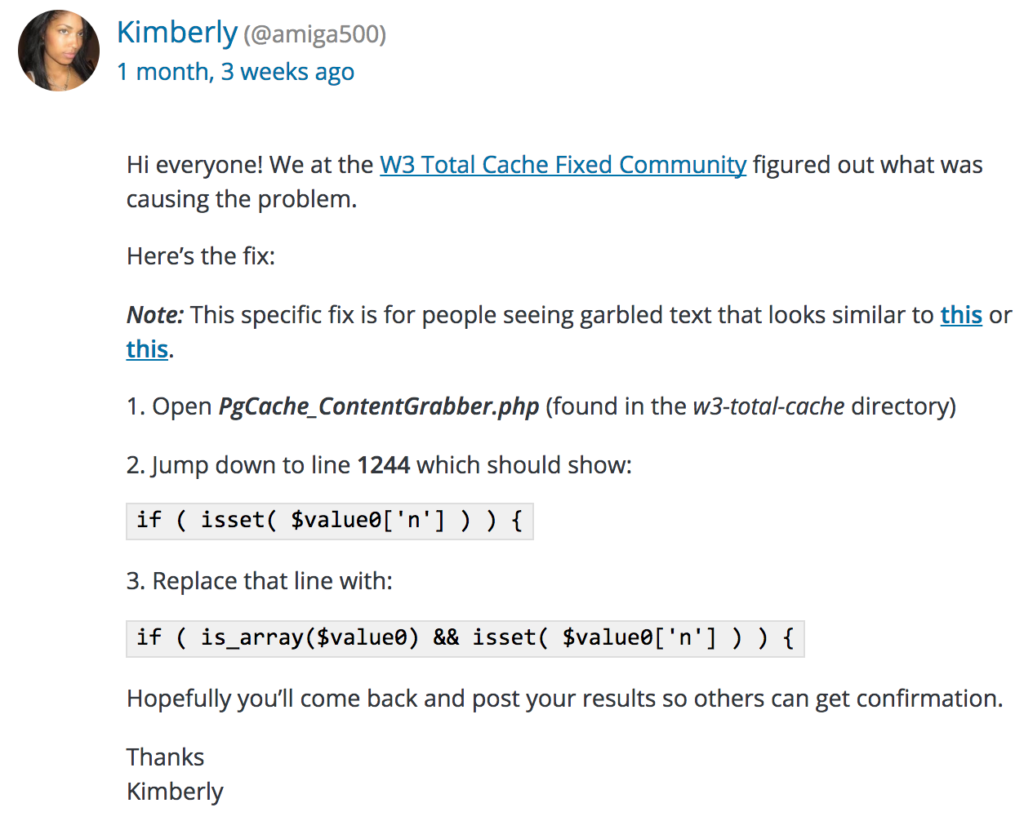
The file for me was at /wp-content/plugins/w3-total-cache/PgCache_ContentGrabber.php.
The instructions were dead on, and so far it appears to work! W3TC creates and caches a gzipped version of each page so that when it needs to serve one to a user, the gzipping has already been done and a static file can be served. This lowers CPU and response time, which is one of the reasons I use the W3TC plugin in the first place. Since not all clients can (or will) accept gzipped pages, there’s also a plain-text version cached in the same directory.
The fix above changes an evaluation line within a function called _headers. Looking more closely it seems that the evaluation assumed that $value0 was an array*, and checked whether $value0[‘n’] was set.
* It may be worth noting here than in PHP, there’s no distinction between list arrays and associative arrays; a plain old list array is pretty much an associative array with keys which are sequential integers. It’s therefore just fine to have a string literal as the index to an array entry.
The updated code checks whether $value0 is an array before trying to access a value using an index. Since this code appears in the _headers function, I think it’s fair to guess that W3TC was sometimes not returning the Content-Type or Content-Encoding value correctly, meaning that browsers were trying to interpret the pages as plain text rather than as a GZIPped document. That’s just a guess, though, as I don’t have time to dig through the calling code to find out for sure. Here’s the function (showing the commented out and replaced line from above):

Whether I’m right or wrong, I really don’t care. I’m just pleased that this solution appears to work! Thanks for sticking with me through Corruptiongate (or whatever we’re calling this catastrophe)!
Leave a Reply