
Last week I posed a question about how an ICMP response would pass through a Juniper SRX firewall. If you need to remind yourself what the scenario was, please take a moment to read the post ICMP Challenge Part 1, because in this post I’m going to run through the answer.
ICMP Response Primer
One of the concerns I heard expressed is that if the SRX were to NAT the source IP of the Fragmentation Needed response, then the original sender would not know to what the ICMP packet referred. That sounds logical, but when you think about it, ICMP actually relies on the fact that any device can send a response back, and for all of those responses, the only IP that the orginal sender knows about is the final destination. And so, ICMP helps out by including the header (or thereabouts) of the packet to which is it a response. Let’s look at that for a moment. Here’s the decode of an ICMP Ping Request (Type8/Code0) being sent from 1.1.1.2 to 192.168.2.19:
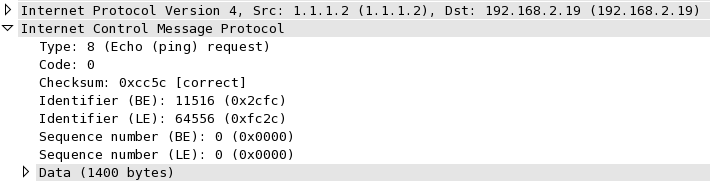
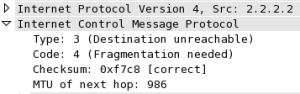
Note that the ICMP decode shows an Identifier and a Sequence Number which WireShark in this case decodes in both Big Endian (BE) and Little Endian (LE) formats for convenience. This particular ping packet has been sent with the Do Not Fragment (DF) bit set and 1400 bytes of data attached, and it’s about to hit a link with a physical MTU of 1000, which is clearly too small for it. Predictably, then, the interface nearest to the original sender generates an ICMP Type3/Code4 (Unreachable, Fragmentation needed but DF-bit set):
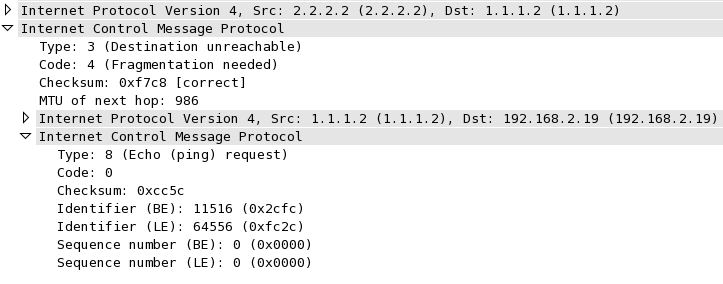
What we see in the decode is an ICMP Type3/Code4 packet sent from 2.2.2.2 back to the original source (1.1.1.2), and a note that the MTU that caused the problem was 986 (remember, physical MTU was 1000, so the protocol MTU will be 14 bytes fewer because the 14 byte Ethernet header is not included). Then nested inside that ICMP message are the IP and ICMP headers from the original packet; including the identifier and sequence number. And that’s how the original sender knows what this ICMP response is all about; it can match up the embedded information and refer it back to the packet it sent. Clever, isn’t it? And that’s how a sending system knows what to retransmit (as a smaller packet that will fit into the stated MTU) when it’s told there’s a problem upstream with MTU.
So from that we can conclude that the source IP of the ICMP response is not important, because the information the sender needs is embedded within the ICMP response. That doesn’t help us at all in answering the question, but it does at least confirm that whether the ICMP message sender’s source IP is NATted or not, it would still work.
Firewall Rules for ICMP
One of my first questions when I began looking at this issue was whether I would need to have a rule allowing ICMP Type3/Code4 outbound or not. The 5-tuple for the ICMP response will not match the existing inbound session, so why would it be allowed out? Is it a global setting to allow this traffic to pass, do I need to add a rule to allow it, or is the firewall smart enough to figure out that the ICMP response relates to an existing session flow?
The answer to this is that the Juniper SRX is smart enough to look inside the ICMP response and associate the ICMP response with the existing flow, and thus the response is allowed out without any need for further rules. In fact, I could not find any way to control this even if I wanted to; I tried adding an ICMP rule higher in the list, but presumably the association with the existing flow happens early on the process (the same way existing flows are handled) so the rule set never even gets a look in. I don’t know if I’d necessarily want to be able to block this particular ICMP response, given that it tries to stop flows from breaking; I’m all in favor of PMTUD working, and it’s considered bad form not to send these responses. For good or bad then, the ICMP response will be passed without a need for a firewall rule to allow it.
And Finally – The NAT Question
I wanted to make sure that I covered the topics above before diving into the answer, because understanding both how the firewall works and how ICMP works are critical to understanding the answer, and why it’s the way it is.
We know that the ICMP response will be sent from the interface nearest to the original source, so the ICMP source will be an RFC1918 IP address. That’s a bad thing if it’s not NATted by the firewall because standard service provider best practices should block any traffic received from a customer with an RFC1918 or bogon source, so it would never make it past the uplink to the Internet.
We also know that we don’t need a firewall rule, and that the response is automatically recognized as being associated with the existing session. I believe that it is this association that causes the firewall not to NAT the outbound ICMP response; the policies – NAT included – don’t even get looked at because of the existing session. See how I cunningly slipped the answer in there? The ICMP response is passed, does not get NATted to the public IP despite outbound NAT policies, and thus will never make it back to the source because it comes from an RFC1918 address. There is no way currently (says JTAC) to change that behavior, although I have made an Enhancement Request (ER) to add some kind of knob to make that behavior tweakable because in this example, we absolutely do want the source IP to be NATted so that it can make it back to the original sender over the Internet. Remember, the source IP address of the ICMP packet is unimportant to the functioning of the ICMP response because of the embedded information.
A Slightly Different Scenario
So what happens if you have destination NAT configured from outside to inside? That is, if the sender hits a public IP on the firewall which is then destination NATted to an internal IP? In that instance, it turns out that (presumably) because there’s NAT in place for the existing security flow, the ICMP packet is source NATted back to that public IP address. So the behavior is different because the existing flow is different and has a NAT component.
Was it worth the wait? I hope so. I find this kind of analysis interesting because it makes me challenge my assumptions about how things should, and actually do, work. I had to lab this up to be sure of the results, and I’m pleased to say that JTAC were able to replicate what I saw, which is always a relief!
What do you think; is this right behavior(s)?
(Updated 2014-02-10: Fixed numerous typos…)

Yup, worth the wait. =-)
IMHO, I think your enhancement request will allow the SRX to behave the way
things should work. i.e. it will allow you to NAT the src of the outbound icmp
packet, so that it will not be dropped by packet filters on the way back to
the original sender.
Good puzzler!
Thanks, Dave. Meanwhile, since I have this problem in production for some host IPs, it’s very annoying to know that if MTU is a problem, I would not be successful in sending back information critical for PMTUD. That kind of sucks…
Interestingly enough, this completely matches the docs I read, which basically stated ICMP Type3/Code4 are always sent. Anyway, interesting write-up. The workaround would be to have the SRX send the message (MSS clamping is supported). I mentioned it on part 1 but in case anyone finds this blog entry via a search later.
http://www.juniper.net/techpubs/en_US/junos12.2/topics/example/session-tcp-maximum-segment-size-for-srx-series-setting-cli.html
Reading the doc rather than glancing at it (which is all I had time to do previously), that’s a real weird way to apply the MSS. Again, it only helps with TCP sessions, although I acknowledge that this means ‘most sessions’ for a typical deployment.
But what gets me is that fact that it seems to be a global flow setting, but in reality there may only be a single zone where there’s a limited MSS, so why punish all the other flows between zones without that limitation? It’s interesting also to see the way this works compared to, say, Cisco’s ‘ip tcp adjust-mss’ interface command. Cisco simply override the MSS in the TCP header (when SYN is set) so that the remote system is asked to use a smaller segment size as part of the TCP establishment. Junos on the other hand approaches this by sending ICMP Type3/Type4 back to the initiator with the appropriate MTU in it. I feel that while Cisco’s approach is a little sneakier, it’s is some ways cleaner (and almost certainly faster). I wonder if there’s a benefit to doing it one way rather than the other?
A final thought is that I don’t believe many – if any – devices allow you to set a minimum MSS that you’ll allow through. That might sound like a stupid ask until you think about a DoS scenario where you initiate many sessions to a device with an MSS of, say, 68 (I think that’s the minimum valid value) and initiate a data transfer. Suddenly the targeted device is having to generating a huge number of tiny packets (with an enormous percentage of overhead compared to the amount of data being sent), which is a great way to totally screw performance. Same applies to load balancers too – they seem to have a similar lack of MSS control. I’d simply reject anything with a tiny MSS (let’s say, less than 536) and deal with the consequences. Ever seen anything for that?
I digress. Based on the description, and what I know about the way some of the firewalls I have managed need to use their zones, I would resent a global MSS command being there; I’d want it at least per zone or per interface to reasonably limit impact to just the interface or zone with the limited MTU.
Love the discussion, by the way – keep it coming, thank you!
Definitely would be a nice enhancement to do this per flow. I meant this is a workaround for this particular corner case. It is not optimal as you pointed out but it will work (the command itself was intended for other scenarios).
Great post. I think too few network engineers are aware of something that will REALLY solve the problem… because the solution does not rely on putting more features in the network. RFC4821 would work wonderfully here because it doesn’t require us network engineers to do anything!
RFC4821 is Packetization Layer Path MTU Discovery (PLPMTUD.) It would involve the end stations, not the network in the middle, to figure out what the MTU is and then adjust accordingly. With PLPMTUD (yes, a difficult acronym) we wouldn’t need ICMP, firewall rules, convoluted NAT rules or JTAC tickets. KISS principal remains king!
RFC3439 actually documents the KISS principal. We should always be asking ourselves “can this be fixed by the end-hosts?” If the answer is YES, have the end-hosts undertake the complex stuff and leave the network hyper-simple.
RFC4821 is very interesting; I took a quick read and it seems quite complex once you dig beneath the general mechanism, and I guess would require a lot of effort to implement. Perhaps that’s why I’ve not heard much in the way of implementations out there. Are there some that you know of?
Definitely appreciate you raising that though, because it’s always good to know about other solutions to a problem! One to watch, for sure.
I agree implementing PLPMTUD into the OS network stack is non-trivial. As network engineers we should be careful to not say “hey, maybe I can make this somebody else’s problem!” and push what should be a network solution into the laps of OS developers. Deploying a fix (or a new feature) in the network means everyone can benefit (possibly immediately) without updating millions of desktops.
But cramming more and more features into the network when the end-hosts should be doing the work is a recipe for creating difficult-to-scale fragile networks. VM mobility comes to mind. OTV, VXLAN, NVGRE can be done (and can sometimes be robust) but didn’t the server people really just need a solid service-name to address resolution protocol that suits their needs? Their app could move across the country, the name mapping system updates (maybe within milliseconds) and then all the clients hit the new location.
Oh, wait. That would mean application developers would have to know something about networking!
Even though PLPMTUD is now an official RFC, I have not heard of any OS implementing it yet. Sadness. Hey, IPv6 came out in 1996 so it only took Windows a billion years to start supporting it. They must have literally two or three programmers over in Redmond working on the network stack. Wake ’em up, tell them to come back from lunch break and let’s suggest IPv6 was not the last network feature they would ever have to implement!
Dan, it’s lovely to hear from somebody who has a sufficiently well-developed sense of cynicism to rival my own 😉
I think there’s a case for both approaches – network and end host. PMTUD is an interesting hybrid I suppose, where the host OS responds (or not) to a message from the network. Ironically of course, the use of PMTUD means setting the DF-bit, and without DF-bit set, the network already knows how to “fix” big packets – fragment them. Fragmentation is not ideal for many reasons of course (ask anybody with a firewall), and may not always be supported. Still, by setting the DF-bit, the host OS is guaranteeing that a large packet will not be propagated, on the assumption that the ICMP response will make it back to them, which – as has been shown many times in the past, as well as in the example in my post – may not always be the case.
In other words, I’m open to host-based PMTU intelligence that does not rely on the network. The challenge will be that even if Microsoft and the linux community (and Apple? 😉 pick up on PLPMTUD today, we’ll be in a world where we still have to support all flavors of MTU discovery for an indefinite period of time. You can’t win, basically.
“application developers would have to know something about networking”… haha. I’m still laughing 🙂
Your comment around PMTUD being a “hybrid” solution is a good one. The network provides some feedback (ICMP Packet-too-big (PTB) message) so the host can do its own adjustment.
IPv4 with the Don’t-Fragment flag turned on produces this result. With DF turned off the router would fragment things, which caused havoc with the CPU.
IPv6 makes one more step in the right direction. It will send an ICMP PTB message but there is no DF flag; the router will never do the job of fragmenting the flow. Good.
IPv7 (or whatever) should take it one more step. Just silently drop the packet. That would force end-stations to support PLPMTUD. It should just be baked into the IPv7 protocol. Done and done.
Of course, let’s not wait for the next version of IP. Let’s do PLPMTUD right now.
If you can control the MTU end-to-end (which obviously isn’t possible for stuff coming in from the Internet), then just jack up the MTU beyond 1500. Find out what the highest supported MTU is across the variety of servers and systems in your environment. We had checkpoint firewalls at one point that only supported 7000 byte MTUs. So everything was 7000 bytes everywhere but the load-balancer/firewall interfaces facing the internet.
It solved many problems. There were benefits we did not expect to see actually. We were just hoping applications would stop breaking. But… lots of things just got better. Link utilization, CPU utilization on routers, CPU utilization on firewalls and IPS’s. CPU and memory on load-balancers. It seemed to just solve a ton of problems. Our FCoIP devices were happier too. Everything was smoother. Especially where flows tended to aggregate massively or where high-throughput was occuring. I wouldn’t say individual flows were “faster,” but latency and CPU utilization were down and traffic peaks were noticably smaller in surface area when looking at graphs.
The downside? Some buffer/QoS tuning had to happen on a number of platforms. For instance, some platforms had a default buffer size of 2*MTU or 3000 bytes. They had to be changed to 14000 bytes. RED had to be tuned on some WAN routers due to how it was implemented by that vendor. If you’re a Cisco guy, you know how buffer tuning is organized by packet sizes… yep… some buffer tuning had to happen there. Analogous (sp?) changes in JUNOS too on some platforms.
Other than those challenges, it was worth it. The headaches caused by fragmentation, weird issues with PMTUD and MSS, it just wasn’t worth fighting. Some things work OK with fragementation, or PMTUD, or MSS… but when you have a large variety of systems and apps, you’re bound to run into stuff that doesn’t play well. Actually the trigger for our decision to jump up the size of the MTU everywhere was an IOS upgrade that broke PMTUD/MSS when using VRFs. We previously had bumped up the MTU on *some* links because JUNOS on M-series service PICs did not support MSS adjust on GRE tunnels (only raw IPSec tunnels at the time). At one point we had access-lists controlling what would have the DF bit cleared and what would not… because some apps would break but others would not. Well that became unmanageable.
Ah well.
Derick,
Great to hear that increasing the MTU had a positive impact on your network. It makes sense that if I need to move 5 GB of data from A to B it will produce less load on the network to do it with >3000 packets (1500-byte MTU) vs. 714 packets (7000 byte MTU.)
Then at one point I read that most of the packet-processing overhead is handled by the end-hosts and with modern hardware (TCP checksum offload in the NIC, etc.) this was no longer a big deal and 1500 was not a limiting factor to performance.
I don’t believe it. Moving the same amount of data with fewer packets will be more efficient. The move to 9000-byte jumbo frames should be a no-brainer.
Then I saw on a Dell white paper that on their iSCSI hardware using jumbo frames I/O operations per second had no speed advantage, but on sequential write bandwidth they saw a 1.5X speed-up and on sequential read bandwidth they got a 3X speed up! There you have it. Jumbo frames rock.
But we should definitely push Microsoft and Linux to support PLPMTUD as soon as possible. If we all switched to 9000-byte packets (or 7000-byte) we would have tunnel overheads somewhere and we’d be right back to worrying about ICMP not doing its job. Let’s think about how we can get to 16,000-byte MTU and the best way to make it work effortlessly.
As I recall, increased minimum MTU was one of the proposals for all IPv6 networks, which is lovely if you have the luxury of doing so, but for the same reasons mentioned above may be somewhat impractical.
With a data center, I’m happy enough with MTU – especially on 10G links – up around 9k. Whether the clients choose to use that, though… well that’s a different matter, because so many of them interact with systems that don’t support 9k, they set their MTU to 1500 anyway. Storage is a great use case for large MTU though.
Perhaps what we really need – for this issue where I can support larger MTUs internally than externally – is a routing table for MTUs (wow, this begins to sound like EIGRP). e.g.
10.0.0.0/8 MTU 9k
0.0.0.0/0 MTU 1500bytes
In other words, default MTU is 1500, but if you’re initiating a flow to an address in this case within 10.0.0.0/8 (i.e. internal to the company), then you’re safe to assume a larger MTU. You’d still need some or all the safeguards previously discussed – whether PLPMTUD or PMTUD/ICMP to protect against non-conforming devices, but still…
This has turned out to be a fascinating disucssion, thanks all!
Well, as I said.. I’m not sure that the performance of individual flows was necessarily better. I’m sure it was the case for some things.
Imagine you have many remote locations and a private network connecting them to head-end data centers. You encrypt with IPSec. These remote locations are hitting a load-balancer in front of some apps. You have a 1500 byte MTU and you clear DF, producing fragments, or you modify MSS, producing more packets.
#1. So you have a head end router that has to decrypt/detunnel that traffic. You have bandwidth those extra packet headers are consuming.
#2. All these extra packets are hitting your load-balancer. In either case, there is CPU overhead for this as those load-balancers wait for packets to reconstruct HTTP payloads. It’s worse when it’s fragments as the IP stack waits to reassemble those packets to then pass up to the another layer which ultimately waits to reconstruct the HTTP payload. In scale, if many users are producing this traffic you end up, of course, with many dropped fragments and packets which futher impacts the system.
#3. Not to mention that any in-line FW/IPS services that might need the fragments to do proper inspection. Some IPS do HTTP level inspection, so they’re still waiting on packets even if you adjust MSS.
#4. Many platforms are not tuned for the extra load of smaller packets.. so buffers grabs are missed… imposing a load on the CPU to generate more buffers. Or just dropping the packet, causing retransmission. True of hosts and routers.
It’s really about head-end aggregation I think, that’s where I was going with this. Bringing many, many sessions into aggregated infrastructure.
Not coincidentally, I imagine, we had a number of well known and unresolved issues, some of them on-going for years, that magically disappeared when we did this. Occasionally a JVM would skyrocket in CPU utilization or there would be a 3 minute period where the app just wouldn’t respond.
Delivering apps with fewer packets, and in particular, with fewer fragments, makes stuff work better.
Another consideration in all of this is default TCP windowing/buffers on end-systems and the use of SACK. I generally recommend to jack up your window sizes and enable SACK. Keep in mind that some very common web platforms like Tomcat ignore system level TCP settings and use their own (or at least, Tomcat used to do this by default) and you have to modify these settings for Tomcat in server.xml. Tomcat has terribly low socket buffer settings by default.
Indeed. I’m not a fan of fragmentation – it causes all sorts of (usually performance) issues with reassembly as well as buffering for retransmission. SACK and large windows are almost essential to keep flows moving quickly. It’s so depressing seeing a high speed flow halt for a bit while it waits for each ACK tor return.
More great thoughts and information, thank you. I am learning a lot today, which means I’m happy!
Very good thoughts about the need for buffer tuning as an implication of raising MTU; I’ll bet that most people have not thought about that when raising it. I’ll have to bear that in mind going forward!
I’m with you that within a data center where you truly control end to end, raising MTU can be a good thing, so long as the NICs etc can still do offload (I have a nagging worry that some would be dumb and pass it up the stack – kind of like process switching versus fast switching!) although that’s based on nothing more than pure paranoia 😉 As you say, though, the moment Internet gets in the picture – and that’s most of the ones I work in – all bets are off I fear.
Thanks for sharing your experience; absolutely fascinating insights!
This will not work. If my workstation lives on a 9k MTU segment and the routing table says the destination is on a 9k MTU segment, I still may not be able to send 9k packets. One or more of the networks in the middle may only support 1500 MTU. Doh!
Sorry. This was in response to the EIGRP suggestion to tag prefixes with an MTU in the routing table.
Indeed – I was only suggesting it to allow an override of a default (safe) MTU in the specific instance where I own and control everything in between. For all other scenarios, you’d use the ‘default route’ MTU. e.g. if I assume that my own networks are all within 10.0.0.0/8 and I know I support 9k MTU everywhere, then I could relatively safely have a 9k MTU default for anything sent to 10.0.0.0/8.
It would definitely be a blunt instrument, to say the least, but might enable high MTU internal transfers while ensuring that flows headed outside of my control are sourced with a smaller MTU to begin with, rather than trying to enforce an adjust-MSS for TCP or something like that.
Could this be a job for LLDP? Push this information all the way out to hosts and let them manage?
Ooh, oooh, DHCP options! After all, we can send entire routing tables via DHCP can’t we? 😉
It might be cool for host to host, but how does one discover end to end MTU?
Ok, that was stupid… I admit it.
If only there was some emerging trend in network technology that might solve this another way with software… hmm.
Start of the art jumbo frames are around 9000 bytes. I haven’t seen gear that does anything much bigger. Just for chuckles…
IPv4 Protocol Max: 65,535 bytes.
IPv6 Max: 65kB
IPv6 Max with Jumbo Payload Option Header: 4GB.
How’d you like to see a single 4 Gigabyte IP packet! Whoa.
Let’s just get to 64kB jumbo frames first and see where we go from there!
Dan, it’s not the 4GB packet that worries me, it’s the retransmission if it got lost or corrupted! 🙂 And good lord, that would play havoc with QoS!
Yeah, maybe 64KB is a nice starting point.
In fact, even 9K would be a nice starting point.
QoS is a sticky one. When I started building networks I still had some customers with 64kbps and 128kbps Frame Relay links. In those days, a 1500 byte packet would take up 187 milliseconds to just push out onto the wire. If your VoIP packet got blocked in the queue behind one of those bad boys it was a lot of latency to deal with.
Fast forward to today, we now have 10Gbps links. If we did have packets that were 64kB large they would only take up 0.051 milliseconds on the wire. If a VoIP packet got blocked behind that mammoth, no problem.
It does really seem funny to be talking about 64kB MTU, but in reality it seems this would cause no QoS problem that I can see.
By the way, in Frame Relay days there were all sorts of kluges to carve up big packets so they wouldn’t block small VoIP packets for too long. Glad we don’t have to deal with those configs anymore!
That’s fine on a 10G link, but now we’re making the assumption that it’s 10G end to end. If there’s anything less than that – especially as you move outwards towards consumers as the network link capacity gets smaller – that 64K suddenly becomes a bigger and bigger problem.
I think in all these discussions we end up back at this problem that it’s the end to end flow that’s the challenge to manage, as it’s usually at least partially out of your direct control.
(And sadly, I’m long enough in the tooth to remember FRF.11 and FRF.12, and I’d be happy never to see them again ;-))