

First, please accept my apologies for the terrible grammar in the title, but really, what better name could I use for a post that is the sequel to “When BGP Aggregates Go Bad“?
Having learned one critical lesson about the redistribution of locally-originated aggregates (described in that last post), I saw an issue recently that could potentially be present in quite a few networks, and the network owners may be totally unaware of it until it’s too late.
BGP Aggregates
Put simply, BGP allows the aggregation of more specific routes into a single route. You can also optionally suppress advertisement of those more specific routes, which along with the creation of the aggregate route provides two immediate (and fairly big) benefits:
- You reduce the number of prefixes that need to be advertised to other BGP autonomous systems, thus reducing the overall size of the BGP tables.
- You effectively hide any flapping of the more specific routes from other autonomous systems, because they only ever see the stable aggregate address.
As long as one or more of the more specific routes are active in BGP, the aggregate will be generated and everbody is happy.
Routing Scenario
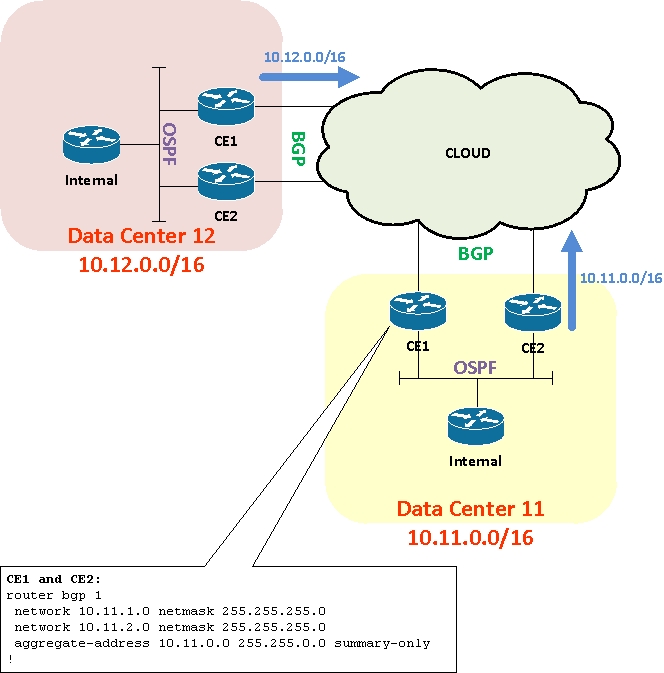
The network architecture above shows two corporate data centers routing to each other over a cloud – it doesn’t particularly matter whether that cloud is a private network, provider MPLS or the Internet. The key point is that BGP is the protocol running at the edge and connecting to the customer edge (CE) routers. We’re responsible architectrs, so we’re dual connected to the cloud from each data center.
Each data center has been given its own chunk of IP space, and while multiple subnets are used within the data center, the edge routers generate a single ‘summary-only’ aggregate route representing the data center’s IP range. The ‘cloud’ therefore only knows two routes – 10.11.0.0/16 and 10.12.0.0/16.
The Problem
Let’s imagine that a large system using 10.11.99.0/24 has to be moved from Data Center 11 to Data Center 12, but cannot be easily re-addressed. This isn’t a huge problem – move the system and simply advertise 10.11.99.0/24 out of Data Center 12. From a routing perspective, this is nothing spectacular. Architecturally (from an IP address summarization perspective) it sucks, but sometimes you don’t get to choose.
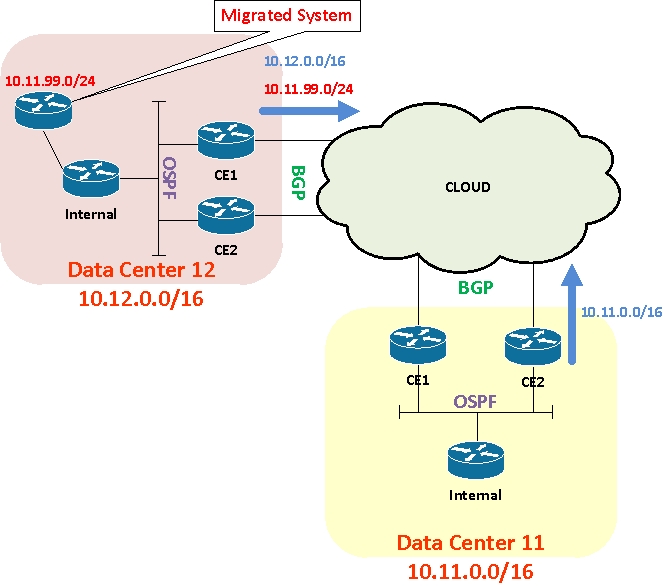
I’ve described one example here, but in principal this problem can be triggered by any scenario where a range of summarized data center IPs are ‘hijacked’ and used elsewhere in the network.
Now let’s think about what happens when the LAN connection on one of the DC11 CE routers goes down:
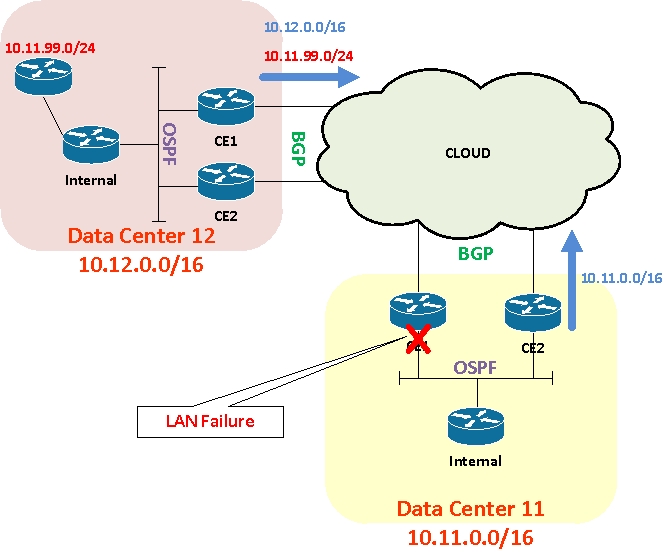
OSPF on the LAN drops, so the BGP routes generated by network statements on that CE will be withdrawn. And that in turn means that the CE will withdraw the BGP aggregate 10.11.0.0/16 advertisement to the cloud.
Wait though; not so fast. While that’s what you might initially expect, that isn’t what happens in this case. Some of you will have already spotted that even though none of the locally originated routes exist, the dead CE will still be receiving 10.11.99.0/24 from the cloud, and consequently it faithfully generates a 10.11.0.0/16 aggregate route and advertises it back to the cloud! Result: traffic traversing the cloud will still see two paths to 10.11.0.0/16 – one via the working CE, and one via the dead CE that will null route the traffic. Potentially half your traffic could be blackholed. With MPLS in the cloud, from some locations, ALL traffic might be lost if the ‘dead’ CE was chosen as the preferred exit point.
There, I Fixed It!
So how do we fix this? There are a few ways one could consider approaching this (and probably more – let me know your ideas in the comments).
- On the CE router, filter routes received from the cloud and don’t accept any (overlapping) 10.11.0.0/16 le 32 routes. That would certainly stop the aggregate being generated, but actually won’t help because having blocked 10.11.99.0/24 from the cloud, you now can’t route to that subnet! Fail.
- Stop using data center subnets outside the data center in which they’re supposed to reside. This is perhaps the most obvious one, but I’m guessing that anybody who has been through a merger or a data center migration will understand why it’s not as easy to do as it is to say. Still, in principal this is the correct approach – don’t allocate even small ranges from your data center subnets for use anywhere except in your data center.
- Stop using the aggregate routes. This fixes the problem, but then increases the number of routes that need to be known in the cloud, and most likely that need to be redistributed at other sites. Depending on the size of your network, that may be an unacceptable compromise.
- Stop using the aggregate routes, and use IP SLA to determine if the LAN is up, and thus whether to advertise a /16 route. Pick what you want to track (although monitoring interface status is a bit lame – you really want to validate IP connectivity confirmation). You’ll end up configuring something like this:
- Add a network statement for 10.11.0.0/16
- Add a static route to null0 for 10.11.0.0/16 with the ‘track’ command on the end (to tie it to an SLA monitor)
- Monitor your ability to get to some reliable next hop on the LAN (e.g. your OSPF neighbors or an HSRP address) in order to determine whether your LAN connection and your desired next hops are available. When they drop, so does your /16 static route, and thus so does your 10.11.0.0/16 advertisement.
- Finally, in order to imitate the ‘summary-only’ part, filter outbound BGP advertisements to deny “10.11.0.0/16 ge 9” – that is any subnet that falls within 10.11.0.0/16.
- Use BGP Conditional Advertisements. I actually quite like this just because it’s all wrapped up in BGP itself, without relying on IP SLA. In this case:
- Retain the original “aggregate 10.11.0.0 255.255.0.0 summary-only” configuration
- Pick a number of 10.11.x.x subnets that have network statements (or are redistributed into BGP) and are learned via your IGP. These will be the BGP routes we’re going to monitor – if they exist in BGP, the IGP must be working, which means the interface must be up. List these in a prefix-list.
- Create a prefix-list permitting 10.11.0.0/16 – this is the route we want to advertise only if the routes above are present in BGP.
- Build a ‘things to monitor’ route-map that permits based on matching on the first prefix-list, and a ‘things to advertise’ route-map that permits based on matches on the 10.11.0.0/16 prefix-listl.
- Configure BGP conditional advertisement (within the BGP router configuration) for the cloud neighbor, e.g.
neighbor a.b.c.d advertise-map THINGS_TO_ADVERTISE exist-map THINGS_TO_MONITOR
Which solution is right? Well ok, I eliminated #1, but the others are all valid options. I’d strive for #2, but are you sure that nobody will ever use an overlapping subnet and advertise it into the cloud in the future? No, nor me.
Danger, Will Robinson!
And so we learn that BGP aggregates are really cool, but we have to be careful how we think about them. In my head – and I suspect many other people’s head too – they can feel a bit like OSPF summary routes, and we think about our own BGP AS as the area that the aggregate summarizes to other areas (or autonomous systems). The reality though is that there’s no split horizon logic going on with BGP – it will happily receive a route from ‘outside’ that triggers generation of an aggregate that is advertised right back where it came from!
Consider yourself warned.
Are You Safe?
Have a think about your own network – do you use aggregates? If so, it is possible that you could get caught by this same problem in the future? A WAN failure, of course, would not be a problem – the CE would be isolated from the cloud and couldn’t cause problems.
Do you have any other solutions or comments on this scenario? Let me know in the comments.



Great post thanks. Like reading about real world problems and solutions as its easy to apply it to your own network, food for thought as I’m considering some inter MPLS cloudBGP aggregation right now!
Hi steve b. we are currently thinking of using aggregate routes in our MPLS. it will the same principle as your MPLS (i.e. inter-mpls cloud bgp). can u share the solution u have deployed on your network?
Thanks a lot for the tips. #5 is pretty great and I was unaware of that feature.
I’m and advocate of #3. I do not like aggregate routing on the WAN because something always comes up – especially with the data center. You’d have to have a ridiculously large number of prefixes for this to be an issue.