
Back in that world where I reinvent the commercially available wheel, I’ve been wondering for a while about how to achieve firewall policy automation in a multi-datacenter environment. This week I started tinkering with possible ways to achieve this, and knocked up some proof of concept code in my favorite untrendy, archaic language, Perl. Don’t say it.

The key issue is that given a firewall request (source IP, destination IP, port) it’s necessary to identify the firewalls and zones to which those rules apply, in order that rules can be automatically built in the right place(s). An additional twist I’ve seen is firewalls that have multiple routing instances, each of which maintains its own set of zones, effectively isolated from each other, even though they’re all on the same firewall.
Graphing Firewalls
I spent a while thinking about ways to model the firewall architecture, and kept on getting caught up on the firewalls with multiple routing instances. Because of the routing isolation, they behave like two separate firewalls, which makes it a little tricky to figure out the correct paths. I also wanted a solution that might also tell me which specific firewall zones were involved in the path; after all, that’s needed to build a rule on a zone-based firewall.
Basic Model
In the end, the model I came up with a model to start playing with. Here’s a simple model of single firewall with three zones, prod, dmz and tier2.
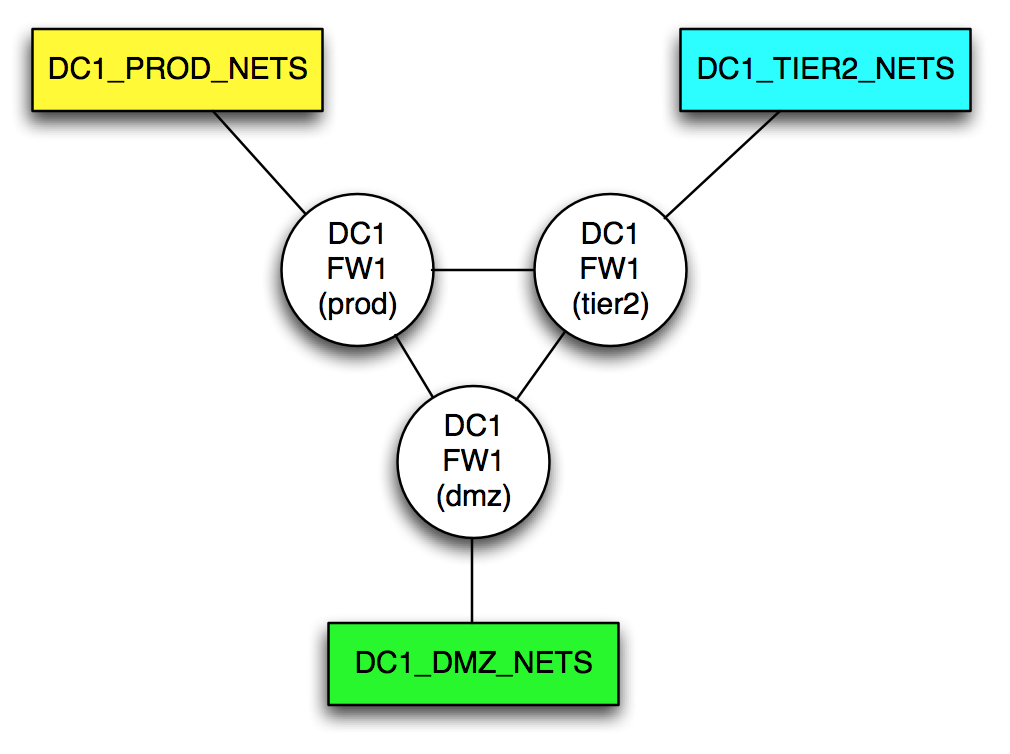
The three circles that look like routers are in fact representations of a single device, each representing a single zone. Logically speaking, each zone is capable (rules notwithstanding) of communicating with all attached zones, thus they are connected in a full mesh. If this looks like a regular network diagram with routers, you’re right on the money.
Let’s develop this a little bit further. I said before that I work with firewalls that have not only multiple zones, but multiple routing-instances (VRFs) which means that not all zones can, in fact, talk to each other. Some networks, however, are attached to both routing-instances, and thus can exist in two zones at the same time.
Adding Routing Instances
For the example network, I will add a routing-instance with two more zones, extra and int. The int zone is connected to the DC1_PROD_NETS. Now the topology looks like this:
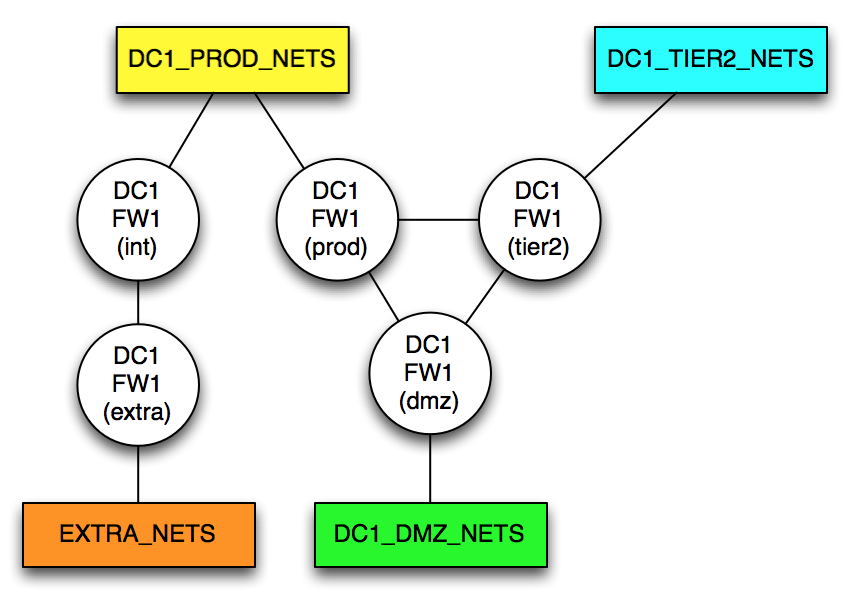
Although there are now apparently five ‘routers’, remember that these are five zones on a single firewall; it’s just that two of them (int and extra) are isolated in their own routing-instance. To get from, say, EXTRA_NETS to DC1_DMZ_NETS, it’s necessary to traverse the firewall twice – trace it out and it’s obvious.
Adding a Second DataCenter
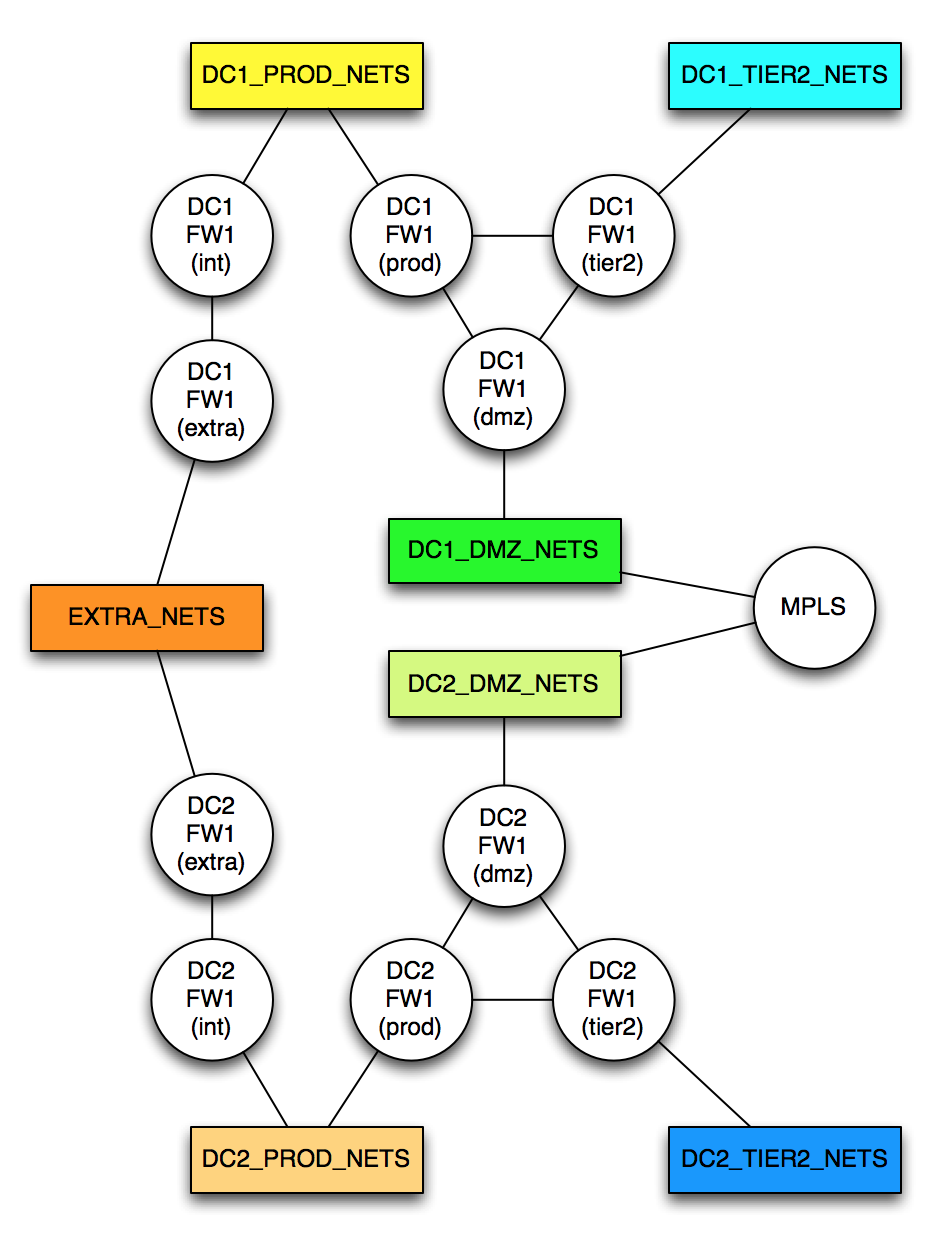
Let’s now add a second data center. It’s identical to the first one, but we also have to connect them together. To that end, I’m also adding that:
- The EXTRA_NETS are true extranet connections, so effectively the same IPs are available regardless of which DC connects to them, so they are shared between the DCs.
- The DMZ_NETS in each DC can route to each other. They aren’t the same subnet (if they were, I’d represent them as the same object on the diagram), but there’s a direct routed path between them over an MPLS WAN network. I’ve added a new object called “MPLS” to represent the WAN cloud.
The topology now looks like this:
You Mentioned Perl?
I mentioned Perl, but before I go there, a couple of quick questions. In the “Two Data Center” diagram:
- What’s the logical path between the DC1_TIER2_NETS and the DC2_TIER2_NETS? How did you figure it out?
- What’s the logical path between the EXTRA_NETS and DC1_DMZ_NETS? How did you figure it out?
My guess is that when you answered, you found the most direct path between each network object. If this sounds like a boring routing problem, well, it is. Specifically, finding the shortest path through a topology (also called a ‘graph’) is something that the Dijkstra algorithm is quite good at, which is why it’s used in OSPF.
If I can model the network then run a Dijkstra algorithm on it, I can easily find the optimal path between two points in my network. I may want to make some cost adjustments for links to make sure, for example, that the EXTRA_NETS are never used as a transit (a super high cost will make sure of that). And by preferring LAN links over WAN links, we can further tune the behavior of the model to mirror the real network.
Writing the Algorithm
Do you think I’m nuts? No. I thought about writing my own algorithm for about 1 minute, after which I said to myself “Hmm, somebody must have written that already,” and discovered that they had, in the form of the module Paths::Graph, and its annoyingly named submodule, Path::Graph. The code required to determine the shortest path is minimal, but the code to build the data structure is definitely significantly more annoying (I’ll explain why later). The Paths::Graph module can take a hash (a data type) containing a representation of the network and the link costs and calculate the shortest path between any two points.
Example Time
1. From DC1_TIER2_NETS to DC2_TIER2_NETS
Shortest path(s):
[DC2_TIER2_NETS] > DC2FW1(tier2) > DC2FW1(dmz) > [DC2_DMZ_NETS] > MPLS > [DC1_DMZ_NETS] > DC1FW1(dmz) > DC1FW1(tier2) > [DC1_TIER2_NETS]
Do you want this to happen? That’s up to you; that’s what firewall policies are for. The point is that from a pure connectivity level, the path exists.
2. From EXTRA_NETS to DC1_DMZ_NETS
Shortest path(s):
[EXTRA_NETS] > DC1FW1(extra) > DC1FW1(int) > [DC1_PROD_NETS] > DC1FW1(prod) > DC1FW1(dmz) > [DC1_DMZ1_NETS]
What does this tell us? This particular flow will require two rules on the same firewall. In Juniper SRX style that would be:
- from-zone extra to-zone int
- from-zone prod to-zone dmz
The traffic will take a routed hop (or hops) within the [DC1_PROD_NETS] routed zone. Which hops, we don’t care; that’s not the point.
Caveats
There are many caveats I can think of, but the fundamental limitation here is that the moment you start route filtering to manipulate traffic flows, the routed topology won’t match the logical topology. That said, if you’re in an environment without such nastiness, this would work.
In my next post, I’ll post some of the perl code for you to laugh at.
Why Bother?
Remember where I started: in order to automate firewall rule deployment, I need a system smart enough to identify which firewalls are in the flow path, across multiple systems, and even where equal cost paths are involved (and just like OSPF, this will calculate equal cost paths).
Roughly speaking those steps in an ideal world might map out as:
- Web interface to get source / dest / ports requested
- Identify where each subnet is located (map to [xxxx_NETS])
- Apply business policies to requested connectivity
- Find shortest path between source/Dest and identify firewalls/zones in the flow
- Deploy policies to identified firewalls using that information
Somewhere in there (whether via business policies or a human approval) there probably should be an authorization step. There’s also some intelligence required about how to deploy the policies and how to minimize the usual policy bloat that can occur, but that’s another discussion.
I dare to dream, right? Look out for the follow up post soon and see how challenging the code isn’t.
Related: Read how automation might impact infrastructure engineering jobs in the future.


Will you be posting the illustrious Perl code on GitHub?
Happy enough to do so, though as you’ll see in Friday’s post, there’s really not much to it. The most complex thing (and it wasn’t very complex) was taking the YAML file and converting it to the necessary hash format for the perl module. The perl itself is, well, minimal! Let me know what you think on Friday?
Hi John,
it’s nice to learn that someone else got the same idea to solve a very similar problem 🙂
This was actually the first approach I took to solve this nasty firewall policy problem.. Since then my scenario is a little different because I can now predict the routing table for each device. That means my script can “walk” through the network and make the same turns as the packet would. The network topology and configuration data is stored in a database.
Another use case is not only to map firewall policies to firewalls (or VRFs) but to keep firewall policies always topology independent. My fellow workmates and I can throw in any IP address/subnet as source or destination. The algorithm will figure out how many policies are needed to get from each source to every destination.
When you extend your first example to a policy from DC1_TIER2_NETS to DC2_TIER2_NETS and DC2_PROD_NETS you will end up with one (best case) policy on DC1_FW1 and two policies on DC2_FW1.
Add a config generator and a push script to that and you are the hero among firewall admins!
That sounds very cool! I considered pulling routing tables (and indeed, it may happen in the future), but decided for a first pass this would be a quick way to get results and validate inputs. However, where routing doesn’t follow the most obvious path, there are definitely flaws in my methodology 😉
Have you posted anywhere about your solution by the way? If not, I’m sure people would be interested!