
Cisco launched their Application Centric Infrastructure (ACI) product two weeks ago in New York City, and I was privileged to be able to attend the event as a guest of Gestalt IT’s Tech Field Day.
Cisco launched some interesting solutions and some potentially great products, but I find myself wondering how this is really going to work and, perhaps more importantly, whether the Nexus 9000 switches and ACI are going to be a solution that will be right for Cisco’s (and my) clients.
I have a few concerns, but first let’s look at why I was at the launch, and what was presented.
Tech Field Day
Courtesy of Tech Field Day (TFD), I had a fantastic time soaking up the collective brainwaves of Amy Arnold (@amyengineer), Chris Marget (@chrismarget), Bob McCouch (@bobmccouch), Jason Edelman (@jedelman8), Pete Welcher (@pjwelcher), Matt Oswalt (@mierdin) and, of course, our delightful host, Tom Hollingsworth (@networkingnerd). And if that weren’t enough, we got to spend time with Amy Lewis (@commsninja), Joe Onisick (@jonisick) and Mike Dvorkin (@dvorkinista) – from Cisco, Insieme and Insieme, respectively. Amy was a wonderful host from Cisco, and – especially as the launch was effectively for the Insieme products – having time with Joe and Mike was amazingly valuable. You would be hard pushed to find two people who are more enthusiastic, technically phenomenal, and utterly serious about their solution.
Application Centric Infrastructure
I’m hesitant to try and explain Cisco’s ACI in too much detail, especially as there are people out there who had access to far more detailed technical information than I got from the launch event itself which, let’s face it, was largely aimed at analysts and investors more than at the techies in attendance. For some pretty hardcore technical details I’m going to refer you to Matt Oswalt’s posts and a podcast, as they’re really quite comprehensive:
The gist of ACI is that in Q1 2014, Cisco will offer a Cisco UCS-based policy controller called the APIC where you can configure application profiles – define what talks to what based on Layer 3, Layer 4, tagging (VLAN or overlay) or port, and apply policies to those conversations. These are configured from the perspective of the service (e.g. “Internet clients talk to web apps”, “web apps talk to mid tier” and “mid tier talks to database tier”), so that the complexity of the network is hidden away from the user. APIC learns the topology (presumably usually a Layer 3 leaf/spine) when it’s connected, and can then program the network to send traffic across the fabric based on the policies that were created in the APIC. Policies can follow servers and applications automatically, so the network effectively self-provisions as hosts move around.
Traffic across the ACI fabric itself is encapsulated in VXLAN, albeit with Cisco using some ‘unused’ bits in the headers to add additional information that ACI can use to manage and track the traffic, though those headers are added at ingress and removed at egress, so it’s nothing ever seen by end devices.
Another point of interest is that the switches will constantly monitor link latency, generating real time latency information for every link in the fabric. If you know the precise latency of a link at any given moment, you can do per-packet load balancing over multiple links and still ensure that the frames arrive in the right order at the other side by calculating the predicted arrival time over each link and sequencing the frames accordingly.

Right now, we tend to do flow-based load-balancing rather than per-packet, in order to avoid out of order packet arrival which chokes up the receiving device; this solution neatly sidesteps that problem and potentially provides better throughput and more optimal use of the network bandwidth.
Hardware Based Networking?
So why is this being considered “Hardware Based Networking” by many observers? Well, Cisco’s ACI solution utilizes a custom ASIC created by Insieme, that sits on the line cards. One of the functions the ASIC performs is the real-time link latency monitoring mentioned above. Additionally it adds extra buffering, allows processing of VXLAN packets without packet recirculation, and generally supports the merchant silicon that provides the basic switching on the cards (in this case, the Broadcom Trident II chipset). In other words, you can’t reap the benefits by deploying APIC on another network; you need to deploy in conjunction with the ACI-enabled line cards.
I took a sneak peak at one of the new Nexus 9500 linecards, and I’m assuming that the large heat sinks are sitting on top of Broadcom silicon, but it’s purely a guess and I’m sure at some point I’ll find out if I’m right or wrong…

Nexus 9000
With a lovely new ASIC to sell, what better idea than to create a new product to sell it in! Cisco has launched the Nexus 9000 series, and as switches go they seem pretty decent. Some good features include:
- Lower power consumption
- No midplane/backplane, so front to back airflow in all chassis
- ACI on the linecards
- BiDI 40GigE optics available
- Only cost ~30% more than 10G optics
- Use existing MMF
- High density 10/40G switching platform
- Cost effective (288 x 10G from $75k ASP)
- Direct automation interfaces (not just via onePK), e.g. OpenStack, OpenFlow, Puppet, Chef, etc.
- NXOS that can run in “Classic” mode or “ACI” mode, allowing you to choose when to implement ACI (although presumably all switches will need ACI enabled for the fabric to work, so it’s a bit of an all or nothing switch I suspect).
40G BiDi Optics
The new 40Gig Ethernet QSFP BiDi optics deserve a special mention as a very interesting development, also from Insieme. By putting 2x20G bidirectional wavelengths down each fiber, the BiDi optic achieves 40G full duplex connectivity through a single multimode fiber pair; specifically the argument is that you can reuse the MMF that is carrying your 10G links today.
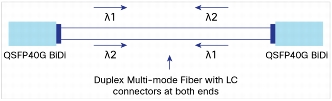
Image from Cisco Systems
That’s a very compelling upgrade path, and when the incremental cost of the 40G optics is so low compared to existing 40G optics, it opens up 40G to many more installations.
Nexus 9k Platform
The Nexus 9000 switches that were announced are:
Nexus 9396PX

The Nexus 9396PX has 48 x 10GE ports and 12 x 40GE QSFP+ uplink ports, all non-blocking, with 2µS latency. Note that there is as much uplink bandwidth as there is host port bandwidth – it’s 1:1, so has the potential to be truly non-blocking.
Nexus 93128TX

The Nexus 93128TX has 96 x 1/10GE ports and 8 x 40GE QSFP+ uplink ports, all apparently non-blocking, with 2µS latency. Reality check: 960Gbps of host ports into 320Gbps of uplink = 3 x oversubscription. I have to assume then that while the 1/10GE ports are non-blocking between themselves, and the 40GE ports are non-blocking between themselves, that the cannot possibly be non-blocking when there’s oversubscription in play. Obviously if you use some of those ports at 1GE, the balance changes, and I guess that’s the point – but do your own calculations based on your mix of 1GE and 10GE ports.
Nexus 9508

The Nexus 9508 is an 8-slot modular switch with three current line card options, the N9K-X9564TX (48 x 1/10GE-baseT with 4 x QSFP), the N9K-X9564PX (48 x 1/10GE optics with 4 x QSFP) and the N9K-X9636PQ (36 x 40GE QSFP). The 1/10GE modules are described as “ACI Leaf” line cards where the 40GE modules is described as an “aggregation” line card. With a claimed 30Tbps of nonblocking performance, the 9508 is clearly no slouch.
Over All
Over all, very clever stuff. The Nexus 9k looks like a pretty good platform with remarkably good 40GE pricing. Cisco envisage you using the 9500 and 9300 as spine and leaf switches respectively.
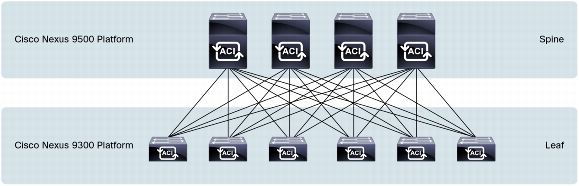
Image from Cisco Systems
There’s no layer 2 involved; it’s all layer 3 as you’d expect, and Cisco’s totally un-ironic use of VXLAN allows layer 2 frames to be transported across this layer 3 fabric.
And Yet…
Despite all the good sounding specs, by the end of the launch I was left feeling a little bit unsure about how this would actually fit into a typical data center and, perhaps more importantly, how it would integrate with the rest of the network and across multiple data centers.
I’ll go into more detail on my concerns in my next post, but it’s safe to assume that I have some pretty strong reservations for now at least. Perhaps as more information emerges, I’ll get answers to some of the questions I have, and maybe I can change my position then.
Disclosure
My travel, accommodation and meals on this trip were paid for by Tech Field Day who in turn I believe were paid by Cisco to organize an event around the launch. It should be made clear that I received no other compensation for attending this event, and there was no expectation or agreement that I will write about what I learn, nor are there any expectations in regard to any content I may publish as a result. I have free reign to write as much or little as I want, and express any opinions that I want; there is no ‘quid pro quo’ for these events, and that’s important to me.
Please read my general Disclosure Statement for more information.


Leave a Reply